Installing PyTorch has no business being so complicated on Linux as it still is in late 2022.
The main problem is that there are four independently moving parts and very little guidance on how to align them:
Python version
PyTorch version
CUDA version
Nvidia drivers version
GPU card
On the first impression, it should work easily no? After all, conda is the de-facto queen of scientific computing, both Pytorch and Nvidia provide configurators for command-line, platform specific installations, PyTorch installation and CUDA drivers installation. Ubuntu is relatively “mainstream” and “corporate”, meaning that there is a single-click choice to install proprietary drivers from NVIDIA that are automatically determined based on the GPU card you have
Right?
Wrong.
For anyone who had a shot at trying to install PyTorch has realized there is an interdependence that’s not always easy to debug and resolve. After a couple of weeks lost a year ago, I was aware of the problem when I was starting to configure a new machine for ML work, but I still lost almost half a day to debug it and make it works.
Specifically, the problem was that NVIDIA CUDA version is currently at 12 (12.1 specifically), whereas the latest version of PyTorch wants 11.6 or at least 11.7, not even the last 11 series release – the 11.8.
For that, we will need to start by checking PyTorch requirements on the official site and choose the last compatible CUDA version. Here it is 11.7.
After that, we go and locate in the CUDA releases archives the relevant version. Here it is the CUDA-11.7.1. However, there is a catch-22 here. The default web installer any sane user would use (add key to keyring + apt-get install) will actually install CUDA-12. Yuuuup. And the downgrading experience is not the best, nor the most straightforward. So you MUST use a local installer command, that pins the version (here).
However, this is not it yet. Before installing CUDA, you need to make sure you have the proper drivers version, that are compatible with CUDA and the graphics card.
The current drivers version for Linux for NVIDIA drivers is 525.XX.XX for my graphics according to Nvidia’s reverse compatibility, fortunately for me it works with CUDA 11.7, otherwise a compatibility pack would have been needed. Moreover, your graphic cards might not be supported by the latest NVIDIA drivers, in which case you would need to work backwards to find the last release of PyTorch and connected packages that would still be supporting the CUDA stack you have access to.
Fortunately for me, it was not the case, so I could start installing things from there.
This could and should have been a one-liner with automated dependencies resolution or at least part of the installation stack on the Pytorch website.
It isn’t.
It’s an outdated installation procedure straight from the 1990s, with user figuring out dependencies and resolving unexpected behaviors from those dependencies.
In 2022 we can and usually do better than that.
Especially for a major toolchain used by millions.
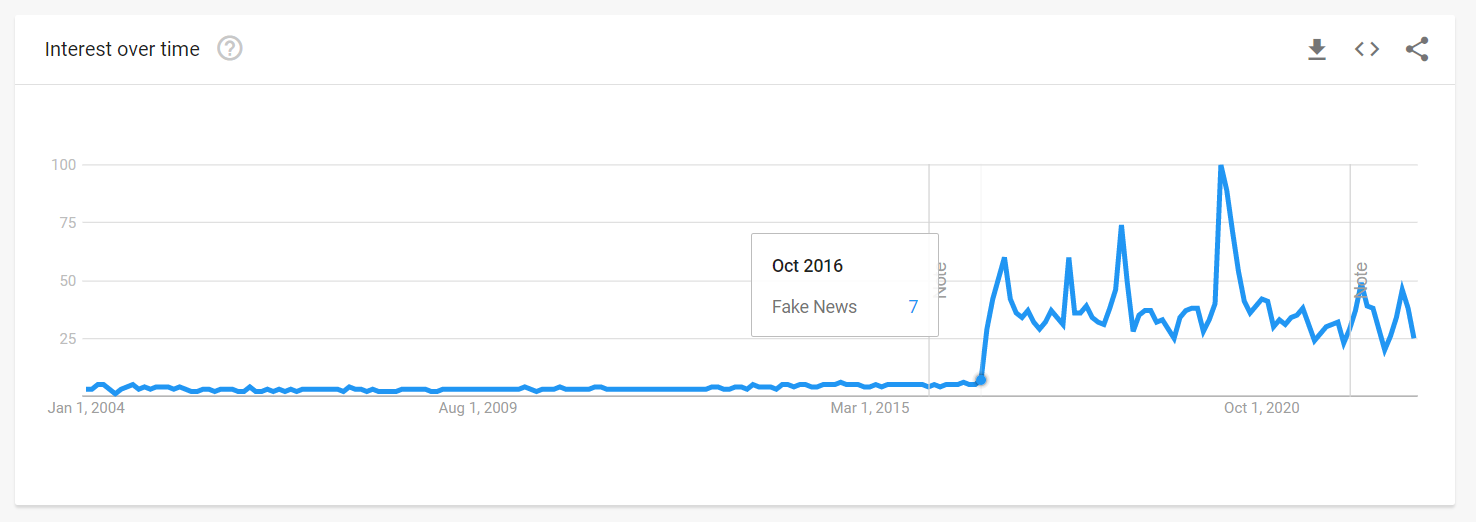
The “Fake News” as a term and a concept became ubiquitous ever since Trump used it in September 2016 to dismiss accusations of sexual assault against him.
Unfortunately, that expression stuck ever since and is now used at large, including by experts in disinformation in their scientific literature.
This is highly problematic.
The ongoing common usage of “Fake News” term is harmful to healthy public discourse and research into misleading information.
Terminology forces a mindframe
Despite what his political opponents wanted to believe, Trump and his allies (notably Steve Bannon) are far from being dumb. While they are con men, they mastered the art of switching public attention away from topics that don’t suit them.
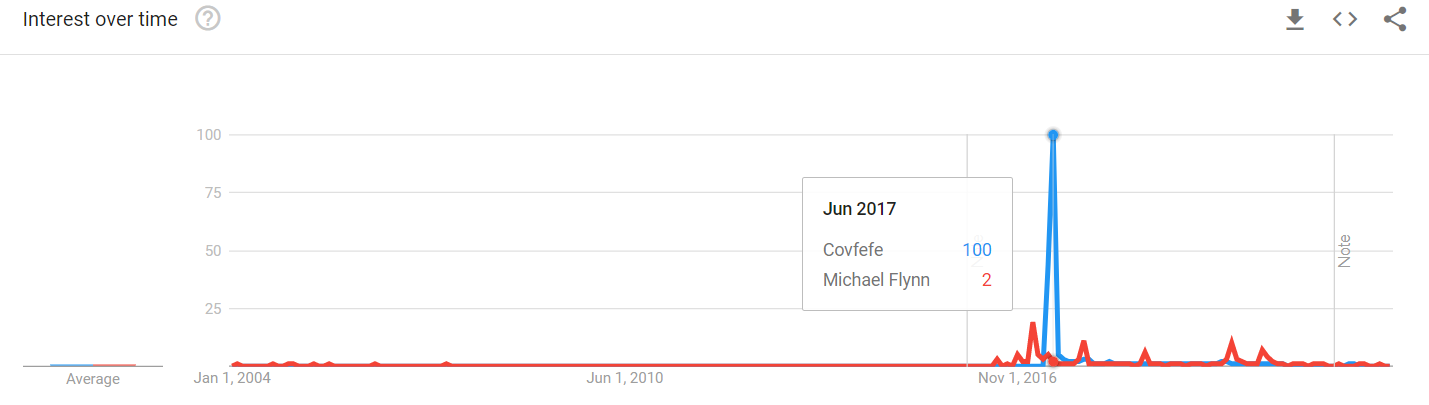
Using a specific vocabulary and terms that “stick” with the public is one of them, and the famous “covfefe” tweet is arguably the most egregious example of it.
“Covfefe” is a modern example of such usage. Michael Flynn pleading 5th and Saudi Arabia “deal” stories were pretty damaging to the image Trump has been trying to maintain with his followers. If gained enough momentum, they could have started eroding his base’s trust in him. A simple “spelling error from a president overtired from making all the hard decisions” can definitely be passed for “liberals nitpicking over nothing” – basically a mirror of Obama’s beige suit or latte salute.
“Fake News” is no different.
“Fake News” transforms public debate into a shouting match
A major issue with “Fake News” is that it stops a public debate and transforms it into a screaming match, based on loyalty. Trump says that accusations of rape against him and the “grab them by the pussy” tape are “Fake News”. Hilary says that his claims of being a billionaire and a great businessman are “Fake News”.
And that’s where the debate stops. Most people will just get offended that the other side is calling obviously true things “Fake News” or persisting in their belief that obviously “Fake News” are real. And their decision regarding what to go is already predetermined by prior beliefs, partisanship, and memes.
Which is exactly what you want when you know in advance that you are in the wrong and will be losing in a proper civil debate.
Which is Trump’s case. Hence the “Fake News”
And it is exactly the opposite of what you want when you are in the right and know you will win over people’s opinions if you have a chance to get their attention.
Which is the case for investigative journalists, scientists, civil rights activists, and saner politicians.
And yet, for whatever bloody reason the latter decided to get on with and keep using the “Fake News” term.
And by doing it, surrendered any edge their position might have had from being rooted in reality.
Just to appropriate a catchy term, even though it is meaningless and can be both a powerful statement and a powerless cry depending on how you see the person saying it.
Major journals publishing an in-depth investigation? Fake news by corrupt media!
Scientific journal publishing a long-awaited scientific article suggesting climate change is accelerating and is even worse than what we expected? Fake news by climate shills!
Are doctors warning about pandemics? Fake news by the deep state looking to undermine the amazing record of president Trump on job creation and economic growth!
Russian media outlets writing a story about the danger of western vaccines? Fake news! … Oh, wait, no, it’s just leftist cultural Marxists propaganda being countered by a neutral outlet!
Basically, by leaving no space for discussion, disagreement, nuance, or even a clear statement, “Fake News” is a rallying cry that precludes civil public debate and bars any chance to convince the other side.
“Fake News” is harmful to public debate.
“Fake News” is too nebulous for scientific research
Words have definitions. Definitions have meanings. Meanings have implications.
“Fake News” is a catchphrase and has no attached definitions. It is useless for scientific process.
How do you define “Fake” and how do you define “News”?
Is an article written by a journalist lost in scientific jargon that has some things wrong “Fake News”?
Is an information operation by a state-sponsored APT using puppet social media profiles to create a sentiment “Fake News”?
Is yellow press with scandalously over-blown titles “Fake News”?
How about a scientific article written with egregious errors that have results currently relevant to an ongoing pandemic – is it “Fake News” too?
Are summaries and recommendations by generative language models such as GPT-Chat “Fake News”, even though it is trying its best to give an accurate answer, but is limited by its architecture?
None of those questions have an answer, or rather answer varies depending on the paper and the paper’s authors’ interests. “Fake News” lacks an agreed-upon operational definition and is too nebulous for any useful usage.
“Fake News” is harmful to the research on public discourse and unauthentic information spread.
Ironic usage is not a valid excuse
An excuse for keeping using the “Fake News” around is that it’s ironic, used in the second degree, humor, riding on the virality wave or calling the calling the king naked.
Not to sound like fun police, but none of them are valid excuses. While the initial use might not be in the first degree, its use still affects thinking patterns and will stick. Eventually, the impact of usage of the term will become more and more natural and start affecting thought patterns, until in a moment of inattention it is used in first-degree.
Eventually “Fake News” becomes a first-degree familiar concept and starts being consistently used.
The harm of “Fake News” occurs regardless of initial reasons to use it.
A better language to talk about misleading information
To add insult to injury, before “Fake News” took over we already had a good vocabulary to talk about misleading information.
Specifically, misinformation and disinformation.
Intention.
Not all misleading information is generated intentionally. In some cases a topic is complex can just be plain hard, and the details making a conclusion valid or invalid – a subject of ongoing debate. Is wine good or bad for health? How about coffee? Cheese? Tea? With about 50 000 headlines claiming both, including within scientific, peer-reviewed publications, it makes sense that a blogger without a scientific background gets confused and ends up writing a misleading summary of their research.
That’s misinformation.
While it can be pretty damaging and lethal (cf alt-med narrative amplification), it is not intentional, meaning the proper response to it is education and clarification.
Conversely, disinformation is intentional, with those generating and spreading it knowing better, but seeking to mislead. No amount of education and clarification will change their narrative, just wear out those trying to elucidate things.
Means
Logical Fallacies are used and called out on the internet to the point of becoming a meme and a “logical fallacy logical fallacy” becoming a thing.
While they are easy to understand and detect, the reality is that there are way more means to err and mislead. Several excellent books have been written on the topic, with my favorites being Carl Bergstrom’s “Calling Bullshit”, Dave Levitan’s “Not a Scientist” and Cathy O’Neil’s “Weapons of Math Destruction“.
However, one of the critical differences between just calling out misinformation/disinformation from “Fake News” is explaining the presumed mechanism. It can be elaborate as “exploited Simpson’s paradox in clinical trial exclusion criteria” or as simple as “lie by omission” or “falsified data by image manipulation“.
But it has to be there to engage in a discussion or at least to get the questioning and thinking process going.
Vector.
No matter the intention or the mechanism of delivery, some of the counterfactual information has a stronger impact than others. A yellow press news article, minor influencer TikTok, YouTube, or a Twitter post are different in their nature but are about as likely to be labeled as untrustworthy. Reputable specialized media news articles or scientific journal publications are on the opposite side of the spectrum of trustworthiness, even though they need amplification to reach a sufficient audience to have an impact. Finally, major cable news segments, or a declarations by a notable public official – eg a head of state – are a whole other thing, percieved as both trustwrothy and reaching a large audience. Calling it out and countering it would require an uphill battle against authority and reputation and a much more detailed and in-depth explanation of misleading aspects.
More importantly, it also provides a context for those trying to spread misleading information. Claiming the world is run by reptilians because a TikToker posted a video about it is on the mostly risible side. Claiming that a public official committed fraud because a major newspaper published an investigative piece is on a much less risible one.
Motivation / Causes.
Finally, a critical part of either defeating disinformation or addressing misinformation is to understand the motivation behind the creators of the former and the causes of error of the latter.
This is a bit harder when it comes to the civil discourse, given that accusations are easy to make and hard to accept. It is however critical to enable research and investigation, although subject to political considerations – in the same way as attribution is in infosec.
Disinformation is pretty clear-cut. Gains can be financial,political, reputational, or military gain, but it’s more of the exact mechanism envisioned by the malicious actor that’s harder to identify and address. They are still important to understand to effectively counter it.
Misinformation is less clear-cut. Since there is no intention and errors are organic, the reasons they emerged are likely to be more convoluted. It can be overlooking primary sources, wrong statistical tests, forgetting about survivorship bias or other implicit selection present in the sample, or lack of expertise to properly evaluate the primary sources. Or likely all of the above combined. They are still important to understand how misinformation emerges and spreads and to stop it.
A couple of examples of better language.
HCQ for COVID from Didier Raoult’s lab
This is a disinformationscientific article, where misleading conclusions were generated by manipulating the exclusion criteria in medical trials and a phony review, motivated by a reputational, political, and likely financial gain.
Chuck Yager’s support of presidential candidate Trump
This is a disinformationsocial media post, that operated by impersonation of a public figure, motivated by adding credibility to Trump as presidential candidate for political gain.
DeepFake of Zelensky giving the order to surrender
This is a disinformationvideo on a national news channel, that was generated using deep generative learning (DeepFake) and injected using a cyber-attack, motivated by immediate military gain resulting from UA soldiers surrendering or at least leaving their positions.
Vaccine proponents are pharma shills
This is a piece of disinformationnews, blog posts, and scientific articles, that were generated by manipulating data and hiding the truth, motivated by financial gains from money given by pharma.
Vaccine opponents make money from the controversy
This is disinformation blog posts, news articles, and videos, that were generated by selecting results and fabricating data, motivated by financial gains from sold books, films, convention tickets, and alt-medical remedies.
Better language leads to a better discussion
The five examples above got you screaming for references for each part of the statement, whether you disagree with them or agree with them.
Good.
That’s the whole point.
Same statements, but as “<X> IS FAKE NEWS” would have led to no additional discussion and just an agreement/disagreement and a slight annoyance.
A single, four-part statement regarding presumably misleading information is harder to form, especially if references are included but is also hard to deny, refute, and just upon being stated will open a door to hesitation and investigation.
Which is the opposite of “Fake News”. Which is what we want.
“Fake News” should be considered harmful and its use – abandoned.
And a lot of people in tech have written about what they think about Mastodon and its future, including ones that I think very highly of, notably “Malwaretech” Marcus Hutchinson (here and here) and Armin Ronacher (here). Go give them a read, they are great insight.
Unlike them, I’ve been on Mastodon on and off (but mostly off) since early 2017, in large part due to missing people I was interested in interacting with there.
Back in 2017 I checked out Mastodon as a potential destination for then nascent science Twitter, if we were kicked off the platform by Trump and his friends, for going againts their agenda.
It might sound a bit paranoid now, but back at the time, NOAA, NSF and EPA archives of climate data and polution were taken down and a certain Andrew Wakefield was invited as a guest of honor at Trump’s Inauguration ceremony. Twitter haven’t taken any stance on fact-checking, scientists harassment or highly vocal antivax propaganda (Vaxxed movie was for instance advertised open and wide there). Facebook was going to roll with whatever the power would have wanted it to do anyway, and for pretty busy MDs and scientists figuring out yet another forum/social network was going to be a hassle. And IRC for sure was out of question.
In hindsight, we might have gone full cyberpunk. And yet, we might have just been on advance on our time.
Five years later, and an aggressively anti-science billionaire hast taken over Twitter and is kicking off anyone he doesn’t like from his platform.
The Great Mastodon Migration(s)
With a lot of people among my contacts now seeing the sign on the wall for Twitter, the issue of Mastodon being empty is now solved for me. I now see there most of the people I followed and interacted on a day-to-day basis on Twitter are now on Mastodon too, mostly interacting in the same way.
Most. And mostly.
As for many tech people and early adopters, I am a bit different from an average user. I am no Linus Torvalds, Steve Wozniak, Dennis Ritchie, or even your middle-of-the road hacker. Bit-by-bit inspection of compiled code to debug or find an exploit is not my idea of good time, but I am still able to jump on a new tech or platform and mostly figure its head and tail, even if it looks off and I need to crawl stackoverflow, reddit and man pages to figure out how to do what I want with it.
Needless to say, I am a minority. A lot of Twitter’s features were getting in the way for me. For instance my timeline has been almost exclusively in chronological and I had add-ons to unfold twitter thread storms into trees to be able to follow it and track people I talked to, because Twitter’s prioritization miserably failed.
But that also meant that Mastodon was a frictionless transition for me. It already worked the way I wanted Twitter to work, except better – more granular control on post visibility, no surprise sponsored posts, and a simpler verification process (rel=”me” FTW!).
It was all but for a lot of my contacts, who struggled to figure out what it was and how it worked.
Roadblocks in the fediverse
Trust into instances.
Twitter is simple. You say to people you are on Twitter, you give them your handle (@JohnDoe) and they can go on Twitter and follow you. @JohnDoe1, @JohnDoe87, @JohnD0e will be other people and you will not be following and interacting with them. With a bit of luck, you are visible enough to earn a blue checkmark and people looking for you will be able to distinguish your account from all the others.
On Mastodon, things are much less clear if you think like a Twitter user.
There is a @JohnDoe@mastodon.social, there is @JohnDoe@infosec.exchange, there is @JohnDoe@SanFrancisco.city. Are they all the same person? If not, which one is the one you need?
If you want to start your account, what does choosing an instance changing?
Which ones will protect your private information, and which ones will get hacked?
Which ones will allow you to follow your friends and which ones will get de-federated? Or block instances your friends are on?
What are the rules of your instance, and who is enforcing them?
Can you criticize and oppressive government? Does your instance admin has enough legal protection to keep you safe against a small dictatorship?
Can you post gore from a recently bombed city to raise awareness, or will it get you kicked or your instance – defederated?
How reliable will the service be? Will you be able to connect when you want to? Or is it going to be a FailPachyderm 24/7?
Over the years, Twitter built themselves a reputation, which made clear what users could expect. At least until Musk nuked it in about 7 days, re-nuking it about once a day since, just in case.
For Mastodon, things are more complicated – basically every instance is it’s own “mini-Twitter” and when push comes to shove it’s not clear if they will stand together or fall one by one. There is some trust towards the largest “mastodon.social”, ran by the Mastodon non-profit itself, but it has no means to scale at the speed of new users arrival, even less to moderate them all. That’s not how Mastodon or Fediverse are supposed to work to start with.
And the problem is that those questions are questions of life and death for opponents to oppressive regimes, citizens trying to survive to them or soldiers on battlefield. Life of protestors in Iran depends on whether the authorities can get to their real name – by injunction or by hacking. Same for women looking for abortion in red states in the US. Ukrainian soldier’s unit depends on whether the instance removes the meta-data from images and reminds them about OPSEC and blurring.
Part of it is educating users and changing the mentality from “it’s Twitter, but for hipster hackers” to “It looks like Twitter, but it’s more of emails”.
Part of it is actually addressing the structural instances right now. A lot of people I’ve heard touching the topic believe it’s not possible without corporate instances making enough profit to protect their users.
I disagree.
No-profits like EFF, La Quadrature du Net, ACLU have been set up specifically to help small organizations with user interests in mind stand up to and fight large organizations with the opposite of user interests in mind. Mozilla, Apache, Linux and Python foundations has been able to provide real-time critical maintenance and support making their products safe to use and deployed with an excellent safety record.
There is no reason those players and foundations couldn’t bring Mastodon foundation up to speed and provide it with instance vetting/certification process and an umbrella coverage to them. It won’t be pre-Musk Twitter, but it might be for the better.
Basically EFF, ACLU and someone like Mozilla need to bring together their powers to create trusted instances and someone like Wikipedia will need to give them a primer on moderation.
Search.
Mastodon does not allow full-text search. Period. That’s by design. You can search for users or hashtags, and you can do full-text searches of your own posts.
You can’t however do a full-text search of your own instance and much less of the fediverse. Once again, that’s by design.
And if you remember the neo-nazi harassment campaign on Twitter against “jewish” accounts back in 2016, with their (((@<account>))), you will agree it makes sense. Besides, fuzzy whole-text indexing and searching are rather expensive operations. In absence of personal data scouring for info that could be used to target ads, it makes no business sense to have it.
However, it also makes Mastodon useless for a lot of people who relied on Twitter to do their job- journalists, scientists, malware analysts, or even critical emergency response.
Journalists were able to zero in on an event or find new information – starting with images posted by some of Jan 6 2021 Capitol Rioters attacks to finding the people combining an in-depth, engaging writing with deep expertise in topics such as COVID. Or find published images of war crimes such as Bucha massacres posted in real time and be able to validate them to make a timely story.
Scientists were able to find people talking about their latest paper or preprint and either address the shortcomings or get a better idea of what to do in the future. Or alternatively look for valid criticism of papers they were going to ask their PhD students to base their work off. With a number of scientific fraud sleuths on Twitter, there are good chances that a search like could lead to project adjustment and save years to the student and hundreds of thousands in funding.
Similarly, Malware analysts could do a deep dive into mentions of CVEs or breach numbers to find ideas others would have regarding patching the system or re-configuring the network to decrease their vulnerability to the attacks.
But perhaps the most critical is emergency incident response. With Twitter, people tweeted about hurricanes hitting them and destroying their houses, cutting water and power, earthquakes they felt, tornadoes that removed their neighbor’s house, smell of gas, symptoms of a disease – you name it. They became essential to the assessment of the situation and decision-making for the search and rescue operations. And given that no one in their right mind would be adding hashtags in their tweets while overwhelmed with feelings and fear, and surely not spelling them right, full-text search was essential to their work.
All of those applications are unquestionable social good and were made possible by Twitter’s full-text search. Mastodon needs to find a way to replicate such search for those applications, even if based on clearances or specific terms.
Commercial content
Another social good that Twitter unintentionally brought with it was companies accountability. Thanks to the search and open APIs (at least for a relatively moderate cost), commercial companies could track their customers sentiment and feedback and jump on anything that could be a request for the support.
While it led to several comical interactions and led to abuse from MLM and web 3.0 Ponzi schemes, the public visibility of their reaction definitely led companies to move it lest they were going to loose customers due to rumors of bad service and bad customer service.
Moreover, a lot of consultants, authors and freelancer lived and died by their Twitter reputation and engagement. LinkedIn is for making pompous announcement in corporatespeak. Twitter is about the “here’s how you do it kids, and here’s the reasons why doing it in that other way is a bad idea”. It was a place to show and prove competence in the domain and get visibility to people who would provide them with contracts and ultimately income. Twitter allowed people more independence and better put forwards their expertise.
However, the reasons they could do it is that they decisionmakers with budgets in their domains already were on Twitter, even if it was for hot takes about the latest sportsball event or to follow a celebrity in hopes to interact with them.
The reality is that commercial content is part of everyone’s life and the way the overwhelming majority of people make money. Mastodon cannot stand on its own if it doesn’t provide a space to talk about it and a space for commercial players to engage at least in some form and people to reach for commercial context in at least some form.
Rules by which commercial companies operate are radically different from FOSS. They need predictability, reliability and protection against impersonation (the whole reason behind Twitter blue checkmarks). There are companies that can do both, but they are few and far in between. And tbh, it’s mostly Red Hat.
Mastodon needs its own Red Hat to emerge and will need to figure out conditions on which the federated instances will let the commercial entities come into fediverse if it is to stand on its own as a social network.
Context
Mastodon home timeline is confusing. At least in the base web interface.
You are greeted with tibits of unrelated conversation without an ability to identify immediately which threads do they fit on, who is that person your friends are boosting, or what is behind that link they are sharing. It just lacks context to be able to fully leverage it.
The <First Tweet> … <Tweets from your friends you haven’t seen yet> feature on Twitter sucked big time – in part because it was impossible to find what the … actually were about unless you got lucky. But it at least provided some context to understand what you were jumping back in.
Similarly, the expansion of URLs into a square that at least includes the header and a short excerpt of the abstract on Twitter was not without its downside, but provided enough context to the link for you to understand what it was about and decide where you were clicking on it.
Finally the show-info-on-hoover for accounts was quite vital to figure out how trustworthy/competent the person behind the post was. Especially once combined with checkmarks (no matter how problematic they were), allowing to tell whether the person really was who they said they were.
Speaking of validation, while the validation is working on Mastodon with the <rel="me"> tag, and could be improved with dedicated instances, they are both prone by domain look-alike squatting. De-facto trust in Web 2.0 is provided by platforms (eg Google search), making sure you are landing on your bank’s account rather than a lookalike built for phishing. Mastodon will need to figure something out, simply because the name or even domain-based trust schema of Web 1.0 is simply too unsafe for the vast majority of users, no matter how tech-saavy.
Similarly, the blue checkmarks is not sufficient context. Yes, an MD with a degree of pandemics preparedness, virology and contagious diseases epidemiology is a good person to listen to regarding COVID news and opinions. An MD with a gastroenterology degree and obesity epidemics expertise is probably not. Yet a blue checkmark is not enough to distinguish them, or even an instance name. There is a need to provide more context about people and their expertise that’s visible at a glance.
Mastodon will need to figure out how to provide enough context while not making editorial decisions and leaving fediverse free, be it with regards to just helping the user or ensuring safety in high-stakes applications.
It might mean that dedicated high-visibility validated instances (EFF/Quadrature/ACLU/Mozilla) will take an outsized importance in the fediverse. It might mean commercial instances. It might mean rules about names proximity. But it will need to be figured out.
Algorithm(s)
The Algorithm is seen as **evil** by the better part of civil liberties advocates, including Mastodon developers and community. The whole promise of Mastodon is to remove the algorithmic censorship of free speech large corporations inevitably put in place and just let you see everything your friends are posting, in the order they are posting.
And I understand that stance. I’ve ran my Twitter feed sorted by newest first most of the time, even after they introduced algorithmic prioritization. It mostly worked for me.
Mostly.
As long as I was following people that were tweeting approximately the same amount of equally important information, it worked well.
It went out of the window as soon as some of them went into a tweeting spike and basically flooded your timeline with retweets of tweets announcing their next event (book signing), or reactions to their latest blog post, or supporting their side in their latest flame war. Good for them, but while scrolling past the tweets of no interest to you, chances you were going to skip something important or critical – like an announcement from an intimate friend for their wedding, promotion, or a prize.
The important signal gets drowned in chaff and meant that even me, with my measly 800 accounts followed had to regularly switch to algorithmic Twitter timeline to catch up on anything I could have missed over the last 4-5 days. For people following the same number of accounts in a more professional setting, the whole chronological timeline becomes an insanity – a non-stop Niagara of new posts rapidly appearing and disappearing as other posts come to take their place. No human can process it all, especially if they spend only a 15-30 minutes a day on that social media.
That’s why prioritization algorithms became popular with users in the first place.
However, algorithms developed by twitter Twitter/Facebook/Google/Youtube/… don’t serve the interest of their users. In the web of ads, attention, engagement and retention are everything. Algorithms built by companies are there to serve the interest of companies first and foremost, user well-being or even safety be damned.
The web of gifting is free of that pressure, but also is lacking resources to develop, train and deploy SotA ML solutions. However SotA is usually not necessary and the benefit of even basic recommendation algorithms is so high that on several occasions I considered writing an independent Twitter client just to have a prioritization algorithm that worked the way I wanted it to.
On Mastodon, it would be at least masking of boosting of tweets I’ve seen before or earlier tweets in a thread I’ve already read by starting from one of the most recent posts. Yes, you can implement your client doing it the way you want, but it’s just not realistic for the vast majority of users – even highly tech advanced. We need a solution about as easy as an “algorithm store”, be it more of a pip or apt or an AppStore. Algorithms can easily be developed by users and shared among them, either for personal use or for distributed privacy-preserving learning.
Mastodon just needs support for personalized algorithms and a way to distribute them and let users choose which ones they want to run.
Moderation
Scaling moderation is a hard task. As of now, the fediverse managed to do it with de-federation and within-instance moderation of federated instances. And lack of valuable targets for harassment,
It is a good solution for the world of small instances and a fediverse with a reasonable amount of instances. With mega-instances, such as for instance the mastodon.social, now at 90 000 users, moderation is unreasonable and smaller instances are already de-federating.
As users will keep migrating into the fediverse (and I do believe they will), there are likely won’t be enough separation of users by interests and communities to avoid mega-instances, especially in the contexts where the likely moderators would impede free speech (eg academic supervisors in academic instances preventing students from warning one another about some top-level academicians’ behaviors).
The moderation of large instances and will become a big problem.
Twitter was riding a thin line between moderating to the point of editorializing and letting abuse run rampant. 2011 Arab Spring protester were on Twitter because it didn’t bulge on their dedication to user protection against abusive regimes – thing on which Microsoft, Google and Facebook didn’t hesitate to bulge. That’s why Arab Spring happened on Twitter. In 2013 peoples who were being vocal about their hate to companies advertising on Twitter were once again let to be vocal rather than de-amplified or outright silenced. That’s how Twitter became the platform to go to with complaints about service or experience and be heard and treated for support in priority. With rampant abuse by state actors seeking to manipulate the public opinion in 2015 and 2016, anti-science disinformation campaigns against vaccines, climate change and pollution in 2016-2019, and then on COVID starting from 2020, and finally Trumps’ call on the insurrection, the moderation became more and more difficult and politicized until fact-checking billionaires brought the demise of Twitter.
However, the most important reason Twitter was credible in their actions was that it opened itself to the external supervision. While Facebook and Google fought against anyone willing to have a look into what was going on their platforms (starting with their own employees), even if it meant they were being complicit in a genocide, Twitter opened it’s platform to researchers for basically free, providing top-tier data access usually reserved for internal use or trusted partners. Even if it meant a deluge of reports came in highlighting hate speech, narratives twisting and information operations, Twitter allowing it and sometimes acting on it still allowed public trust into Twitter as platform, as it was eroding to pretty much everyone of its competitors. It all led people believe Twitter was a hellsite. In reality, it was better than others, just not censoring reports about the problems it might have had.
The mechanisms driving those issues haven’t gone anywhere. They are still here and will start impacting Mastodon and fediverse as it grows.
FOSS doesn’t have billions in ad, premium or VC money to throw at the problem like online giants do.
However it is able to leverage the goodwill and gift of the time from its users as volunteers to achieve the same thing.
Wikipedia, among all, achieved a ubiquitous status as the last instance of truth in the internet, in large part thanks to the moderation model it is running, letting people argue with facts, publicly available information and academic writing until they get to a stalemate that’s pretty representative of the scientific consensus or public knowledge about facts.
It has pretty big issues, notably with women and minorities representation or coverage from minorities narratives. It still did a better job than most large platforms, to the point they started using Wikipedia information in their own moderation decisions.
But Mastodon is not Wikipedia. Fediverse will need to keep figuring out its moderation rules, especially as the stakes keep rising as more and more users join it and larger and larger instances emerge.
Hitting the main street.
I am optimistic about Mastodon and fediverse overall, in large part because it’s a protocol and a walled garden.
And also perhaps because I really want it to work out.
For all its shortcomings, pre-Musk Twitter was a great tool and in a lot of ways made transformations in this world possible, ranging from democratic revolutions to people just getting a better customer service.
And for all its past greatness, Twitter to me is now dead, because what was making it so unique – trusted moderation team – is now dead and will not be coming back to it.
For me personally, the mix of pretty much everyone on there – ranging from scientific colleagues to infosec and disinformation experts, to OPSEC experts to journalists and columnists allowed me to keep the hand on the pulse of the world, professionally, and have the best insight possible not only into the current state, but also project into the future, often further than most other news outlet would have allowed me to.
Unlike a lot of my colleagues, I don’t think that the lack of average Joes on Mastodon is such a big issue for scientific outreach. After all most people don’t listen to some random dude on the internet. They are listening to their local opinion leader, someone they know knowledgeable in their domain, and whose opinion they think extends to other domains. If those people are connected, the outreach still works out.
I also don’t see people coming back to Twitter if the management has a sudden change of heart and a new management comes in. Trust is really slow to build and is easily lost. There is no guarantees new Twitter won’t go deleting users’ critical comments, banning accounts on a whim or perform algorithmic manipulations. People in tech are painfully aware of it; journalists are becoming more and more aware and the general public who don’t care for it, also don’t see any advantages to Twitter over Facebook, TikTok, Instagram or a myriad of other, more engaging and less serious social medias.
Similarly, unlike a lot of my contacts over on Twitter, I don’t think that a social media being commercial is a fatality. I am seeing Mastodon evolving and becoming a healthier alternative to the social media while keeping good things about them and dropping the less good things. FOSS worked out in the past, there is no reason it has to fail now.
In the end, thanks to Musk, Mastodon is now alone in the field, ready to grow and provide to people a better alternative. The only thing that could undermine its growth is itself – its users and its developers.
But that’s a part of the deal. I certainly hope they will find a way forwards and be willing to accept change, no matter how scary.
(This post is part 1 of a series trying to understand the evolution of the web and where it could be heading)
For most of the people in tech, the blockchain/crypto/NFTs/Web 3.0 have been an annoying buzz in the background for the last few years.
The whole idea of spending a couple of hours to (probably) perform an atomic commit into a database while burning a couple of millions of trees seemed quite stupid to start with. Even stupider when you realize it’s not even a commit, but a hash of hashes of hashes of hashes confirming an insertion into a database somewhere.
Financially speaking, the only business model of the giants of this new web seemed to be either slapping that database on anything it could be slapped on and expecting immediate adoption, or a straight-out Ponzi scheme (get it now, it’s going to the moon, tomorrow would be too late!!1!1!).
Oh, and the cherry on the top is that the whole hype machine around Web 3.0 proceeded to blissfully ignore the fact that Web 3.0 has already been popularized – and by no one other than Tim Berner-Lee almost a decade ago, referring to the semantic web.
Now that the whole house of cards is coming crumbling down, the sheer stupidity of crypto Web 3.0 seems self-evident.
And yet, VCs who should have known better have poured tens of billions into it, and developers with stellar reputations have also jumped on the hype train. People who were around for Web 1.0, .com burst, Web 2.0, and actually funded and built the giants for all of them seemingly drank the cool-aid.
Why?
Abridged opinionated history of the InterWebs
Web 1.0
The initial World Wide Web was all about hyperlinks. You logged into your always-on machine, wrote something in the www folder of your TCP/IP server directory, about something you cared about, while hyper-linking to other people’s writing on the topic, and at the end hit “save”. If your writing was interesting and someone found it, they would read it. If your references were well-curated, readers could dive deep into the subject and in turn hyperlink to your writing and to hyperlinks you cited.
If that sounds academic, it is because it is. Tim Berner-Lee invented Web 1.0 while he was working at CERN as a researcher. It’s an amazing system for researchers, engineers, students, or in general a community of people looking to aggregate and cross-reference knowledge.
Where it starts to fall apart, is when you start having trolls, hackers, or otherwise misbehaving users (hello.jpg).
However, what really broke Web 1.0 was when it got popular enough to hit the main street and businesses tried to use it. It made all the sense in the world to sell products that were too niche or for a physical store – eg. rare books (hello early Amazon). However, it was an absolute pain for consumers to find and evaluate the reputation of businesses on the internet.
Basically, as a customer looking for a business, your best bet was to type what you wanted into the address bar followed by a .com (eg VacationRentals.com) and hope you would get what you wanted or at least a hyperlink to what you wanted. As a business looking for customers, your best bet was in turn to try to get the urls people would likely be trying to type looking for the products you were selling.
Aaaand that’s how we got a .com bubble. The VacationRentals.com mentioned above sold for 35M at the time, despite the absence of a business plan, except for the certainty that someone will come along with a business plan and be willing to pay even more, just to get the discoverability. After all, good .com domains were in a limited supply and would certainly only get more expensive, right?
That definitely doesn’t sounds like anything familiar…
Google single-handedly nuked that magnificent business plan.
While competing search engines (eg AltaVista) either struggled to parse natural language queries, to figure out the best responses to them, or to keep up to date in the rapidly evolving Web, Google’s combination of PageRank to figure the site reputability and bag-of-words match to find ones the user was looking for Just Worked(TM). As a customer, instead of typing into an address bar a url you could just google it, and almost always one of the first 3 results would be what you were looking for, no matter the url insanity (eg AirBnBcom). Oh, and on top of it, their algorithms’ polishing made sure that you could trust your results to be free of malware, trolls, or accidental porn (thanks to Google’s company porn-squashing Fridays at Google).
As a business, your amazing .com domain was all of a sudden all but worthless and what really mattered was the top spot in Google search results. The switch of where discoverability budgets were going led to the .com bubble bust, and Google’s AdWords becoming synonymous with marketing on the internet. If you ever wondered how Google got a quasi-monopoly on ads online, you now know.
While Google has solved the issue of finding businesses (and incidentally knowledge) online, the problem of trust remained. Even if you got customers to land your website, it was far from guaranteed that they trust you enough to share their credit card number or just perform a wire to an account they’ve never seen before.
Web of Trusted platforms emerged around and in parallel to Google but really became mainstream once the latter allowed the products on them to be more easily discovered. Amazon with customer reviews, eBay, PayPal, … – they all provided the assurance that your money won’t get stolen, and if the product won’t arrive or would not be as advertised, they would take care of returns and reimbursement.
At this point, the two big issues with Web 1.0 were solved, but something was still missing. The thing is that for most people it’s the interaction with other peoples that matter. And with Web 1.0 still having been built for knowledge and businesses, that part was missing. Not only it was missing for users, but it was also a business opportunity, given that word-of-mouth recommendations are still more trusted than ones from an authority – no matter how reputable, and that users can reveal much more about their interests while talking to friends rather than with their searches.
Web 2.0
If Web 1.0 was about connecting and finding information, Web 2.0 was all about building walled gardens providing a “meeting space” while collecting the chatter and allowing businesses to slide into the chatter relevant to them.
While a few businesses preceded it with the idea (MySpace), it was really Facebook that hit the nail on the head and managed to attract enough of the right demographic to hit the jackpot with brands and companies wanting access to it. Perhaps part of the success of the virality was the fact that they started with two most socially anxious and least self-censoring communities: college and high-school students. Add the ability to post pictures of the parties, tag people in them, an instant chat that was miles ahead of any competition when it came to reliability (cough MSN messenger cough), sprinkle some machine learning on top and you had hundreds of millions pairs of attentive, easy to influence eyeballs, ready to sell to advertisers with little to no concern about user’s privacy or feelings (Are you missing ads for dating websites on FB when you changed your status to “it’s complicated”? or ads for engagent rings if you changed it to “in a relationship”?).
However the very nature of Facebook also burnt out their users and made them leave for other platform. You ain’t going to post your drunken evenings for your grandma to see. Nor will you want to keep in touch with that girl from high school who went full MLM. Or deal with the real-life drama that was moving onto that new platform: nightly posts about how much he hated his wife from your alcoholic oncle, your racist aunt commenting on your cousin’s pictures including a black guy in a group, …
And at that point Facebook switched from the cool hip kid to the do-all weirdo with a lot of cash, that kept buying out newer, cooler platforms – Gowalla, Instagram, What’s App, VR, … At least until anti-trust regulation stepped in when they tried to get to Snapchat.
Specialized social media popped up everywhere Facebook couldn’t or wasn’t yet moving into. LinkedIn allowed people to connect for their corporate needs. Yelp, Google Maps, and Foursquare allowed people to connect over which places to be. Tumblr, Pinterest, 9gag, and Imgur allowed people to share images – from memes to pictures of cats and dream houses. Or just generally be weird and yet engaging – such as Reddit and Twitter.
However, most of the social networks after Facebook had a massive problem – generating revenue. Or more specifically attracting businesses into advertising on them.
The main reason for that is that to attract enough advertisers, they need to prove they have enough reach and that their advertisement model is good enough to drive conversions. And for that, you need a maximum outreach and a maximum amount of information about the people your advertisement goes to. So unless you are going with Facebook and Google, you either need to have a really good idea of how a specific social media works or you pass through ad exchanges.
In other terms, you and your users are caught in a web of ads and as a social media, you are screwed both ways. Even if you are rather massive, there might not be enough advertisers to keep you afloat with your service still remaining usable. Despite its size and notoriety, Twitter failed to generate enough revenue for profitability, even 16 years in. YouTube, despite being part of the Google ecosystem is basically AdTube for most users. If you pass through ad exchange networks, you are getting a tiny sliver of ad revenue that’s not sufficient to differentiate yourself from others or drive any development. Oh, and nothing guarantees the ads that will get assigned to you will be acceptable to your userbase and not loaded with malware. Or conversely that the advertisers’ content won’t show up next to content they don’t want to be associated with their brand, at all.
The problem is not only that this model had razor-thin margins, but it was also increasingly brought under threat by the rising awareness about privacy issues surrounding the ad industry, and the use of information collected for ads against them. Not only for reclusive German hackers concerned about the NSA in the wake of Snowden’s revelations but also for anyone paying attention, especially after the Cambridge Analytica scandal.
Web of Taxed Donations (or world of microtransactions) was the next iteration to try to break out of it.
A lot of social media companies noticed through their internal analytics that not all users are equal. Some attract much more attention and amass a fandom (PewdiePie). Some of those fans are ready to pay some good money to get the attention of their idol (Bathwater). Why add the middleman of ads they don’t want to see anyway rather than allow them to do direct transfers and tax them? Especially if you are already providing them a kickback from ad revenue (because if you aren’t, they are leaving and taking their followers with them)?
Basically, it’s like Uber, but for people already doing creative work in cyber-space (content generators). Or, for people more familiar with gaming – microtransactions. Except instead of a questionable hat on top of your avatar, you are getting a favor from your favorite star. Or remove an annoyance in the way between you and them, such as an ad. Or get a real-world perk, such as a certificate or a diploma.
EdX started the move by creating a platform ot much providers and consumers for paid online classes and degrees. YouTube followed by adding Prime and Superchats, Twitch – subscriptions and cheers, and Patreon decided to roll in and provide a general way to provide direct donations. However, it was perhaps OnlyFans, completely abandoning any ads in favor of direct transactions that really drove the awareness of that income model (and accelerated Twitter’s downfall), while Substack did the same for high-quality writing.
The nice thing about that latter model is that it generated money. Like A LOT of money.
The less nice thing is that you have to convince creators to come to your platform, competing with platforms offering a better share of revenue, and then you need to convince people to sign-up / purchase tokens from your platforms. All while competing with sources funded by ad revenue and the money people spend on housing food, transportation, …
Basically, as of now web 2.0 is built around convincing the user to generate value on your platform and then taxing it – be it by them watching ad spots you can sell to businesses, or directly loading their hard-earned cash onto your platform, to stop annoyance, show they are cooler or donate it to creators.
Now, if we see the web as a purely transactional environment and strip it of everything else, you basically get a “bank” with “fees”. Or a “distributed ledger” with “gas fees”
Crypto Web 3.0
And that’s the promise of Crypto Web 3.0. The “big idea” is to make any internet transaction a monetary one. A microtransaction. Oh, you want to access a web page? Sure, after you pay a “gas fee” to its owner. You want to watch a video? Sure, after you transfer a “platform gas fee” for us to host it and a “copyright gas fee” to its creator.
Using cryptographic PoW-based blockchain for transactions when the “creators” were providing highly illegal things was far from stupid. You can’t have a bank account linked to your identity in case someone will rat you out, or the bank realizes what you are using money for. Remember Silk Road? Waiting a couple of hours for the transaction to clear and paying a fee on it that would make MasterCard, Visa and PayPal salivate was an acceptable price to get drugs delivered to your doorstep a couple of days later. Or get a password to a cache of 0-day exploits.
However, even in this configuration, the crypto had a weak point – exchanges. Hackers providing a cache of exploits have to eat and pay rent and electricity bills. Drug dealers have to pay the supplier, but also eat and live somewhere.
So you end up with exchanges – places that you trust would give you bitcoins someone is selling for real cash and when you want to cash out they will exchange them for real money. Basically Banks. But with none of the safety a bank comes with. No way to recover stolen funds, no way to discover the identity of people who stole them, no way to call Interpol on them, no insurance on the deposits – nothing.
You basically trust your exchange to not be the next Mt. Gox (good luck with that) and you accept it as a price of doing shady business. It’s questionable, and probably a dangerous convenience, but it is not entirely dumb.
What is entirely dumb, however, is trying to push that model mainstream. Those hours to clear a transaction? Forget about it – people want their coffee and bagel to go delivered in seconds. Irreversible transactions? Forget it – people send funds to the wrong address and get scammed all the time, they need a way to contest charges and reverse them. Paying 35$ to order a 15$ pizza in transaction fees? You better be kidding, right? Remembering seed phrases, tracking cold wallet compatibility, and typing 128 char hexadecimal wallet addresses? Forget it, people use 1234546! as a password for a reason and can’t even type correctly an unfamiliar name. Losing their deposited money? Now that’s absolutely out of question, especially if that’s any kind of more or less serious account.
So basically you end up with “reputable” major corporations that do de-facto centralized banking and promise that in the background they do blockchain. At least once a day. Maybe. Maybe not, it’s not like there are any regulations to punish them if they don’t. Nor with any guarantees for standard banks – after all the transactions are irreversible, frauds and “hacks” happen and it’s not like they are affected by the FIDIC 250k insurance. Oh, and they are now unsuited for any illegal activity because regulators can totally find, reach and nuke them (cf Tornado with Russian money after the start of war in Ukraine).
Oh, and on top of all of that, every small transaction still burns about a million trees worth of CO2 emissions.,
Pretty dumb.
But then it got dumber.
The NFTs.
Heralded as the poster child for everything good there was going to be about Web 3.0, they were little more than url pointers to jpeg images visible to anyone and not giving any enforceable rights of ownership. Just an association of a url to a wallet saved somewhere on a blockchain. Not like it was benefitting the artist either – basically the money goes to whoever mints them and puts them for an auction, artist rights be damned.
And yet somehow it worked. At the hype peak, NFTs were selling for tens of millions of dollars. Not even 2 years later, it’s hundreds of USD, at best. Not very different from beanie babies. But probably people getting them weren’t around for the beanie babies craze (made possible by eBay btw).
And VCs in all of that?
Silicon Valley invests in a lot of stupid things. It’s part of VCs mentality over there. And I don’t mean it in a bad way. They start out on the premise that great ideas look very stupid at first, right until they don’t. Very few people would have invested in a startup run by a 20-year-old nerd as a tool for college bro creeps to figure out which of their targets was single, or just got single, or was feeling vulnerable and was ripe to be approached. And yet when Facebook started gaining traction on campuses, VCs dumped a bunch of money into it to create the second biggest walled garden of Web 2.0 (and enable state-sponsored APT to figure out ripe targets for influence operations).
However, Silicon Valley VCs also are aware that a lot of ideas that look very stupid at first are actually just pretty stupid in the end. That is why they invest easily a bit, not rarely a lot, expecting 95-99% of their portfolio to flop.
And yet despite the shitshow FTX was, it still got 1B from VCs (if I am to trust Cruncbase, at a 32B valuation).
Perhaps it’s Wall Street golden boys turned VCs? Having fled investment banking after the 2008 collapse, they had the money to find a new home in Silicon Valley, make money with fintech and move on to being VCs themselves?
That would make sense – seeing crypto hit the main street during its 2017 peak, and seeing no regulations in place after it all crashed, the temptation to pull every single trick in the book that was made illegal by SEC in traditional finance would be pretty high. With households looking for investment vehicles for all the cash they amassed during lockdowns, crypto could be presented well as it was being pumped, at least as long as it could be made to look like it was going to the moon.
There is some credibility to that theory – massive crypto dumps were synchronized with FED base rate hikes to a day, in a way highly suggestive of someone with a direct borrowing line to FED to get leverage.
And yet it can’t be just it. The oldest and most reputable Silicon Valley VCs were onboard with the crypto hype train, either raising billions to form Web 3.0 investment funds or suggesting buying one coin over others.
But why?
While I am not inside the head of the investors with billions at their fingertips, my best guess is that they see the emerging taxed transactions Web 3.0 as ready to go and the first giant in it ready to displace major established markets – in the same way Google did for .com domains with its search.
Under the assumption that the blockchain was indeed going to be the backbone of that transactional web, and given the need for reputable actors to build a bridge with the real cash, it made sense that no price was too high to be onboard of the next monopoly, and a monopoly big enough to disrupt any major player on the market – be they ad-dependent or direct donation dependent.
But given the limitations of the blockchain, that latter assumption seemed… A bold bet to say the least. So maybe they also saw a .com bubble 2.0 coming up and decided to ride it the proper way this time around.
The curious case of hackers and makers.
While it makes sense that VCs wanted a crypto Web 3.0, it also attracted a number of actual notable makers – developers and hackers whose reputation was not to be made anymore. For instance, Moxie Marlinspike of Signal fame at some point considered adding blockchain capability to it. While he and a lot of other creators later bailed out, pointing out the stupidity of Web 3.0, for a while their presence lent the whole Web 3.0 credibility. The one crypto-fans still keep clawing to.
But why?
Why would makers be interested in transactional web? Why would they give any thought to using blockchain, despite having all the background to understand what it was? There are here to build cool things, even if it means that little to no revenues get to them, with the Linux kernel being the poster child for the whole stance.
Well.
The issue is that most makers and creators eventually realize that you can’t live on exposure alone and once a bunch of people start using your new cool project, you need to find money to pay your salary to work on it full time, salaries of people helping you and eventually servers running it, if it’s not self-hosted.
And the web of untaxed donations (or web of gifting) will only take you so far.
Wikipedia manages to rise what it needs to function yearly from small donations. But that’s Wikipedia. And Jimmy has to beg people 2-3 times a year for donations by mail.
Signal mostly manages to survive off donations, but on several occasions, the new users inflow overwhelmed the servers, before the volume of donations caught up with the demand, with the biggest crunches coming right around the moments when people need the service the most – such as at the start of the Russian invasion of Ukraine early this year.
Mastodon experienced it first hand itself this year, as waves after waves of Twitter refugees brought most instances to their knees, despite this specific case having been the original reason for Mastodon’s existence.
That scaling failure is kinda what happened to Twitter too. After Musk’s takeover and purges, Jack Dorsey went on record saying that his biggest regret was to make a company out of Twitter. He is not wrong. His cool side project outgrew his initial plan, without ever generating enough revenue to fund the expenses on lawyers when they decided to protect activists on their platform during the 2011 Arab Spring, then moderation teams in the wake of 2016 social platform manipulation for the US presidential election, content moderation in 2020-2022 to counter disinformation around COVID pandemic, or sexual content moderation in late 2021 and 2022. A non-corporate Twitter would have never had the funds to pull all those expenses through. (And even a lot of corporations try to hide the issue by banning any research on their platforms).
It kinda would make sense in a way that he now is trying to build a new social media, but this time powered by crypto and in web 3.0.
Not that the donations don’t work to fund free-as-in-freedom projects. There is just so much more that could be funded and so much more reliably if there was a better mechanism for a kickback to fund exciting projects. One that would perhaps have avoided projects shutting down or going corporate despite neither the developers, maintainers, or users really wanting it.
From that point of view, it also makes sense that the payment system underlying it is distributed and resilient to censorship. Signal is fighting off censorship and law enforcement, and going after its payment processor is one of the fastest ways to get it.
So it kinda makes sense, and yet…
Into the web of gifting with resilient coordination?
Despite the existence of Web 3.0 alternatives, when Twitter came crashing down, people didn’t flock to them, they flocked to Mastodon, caring little about its bulky early 2010s interface, intermittent crashes, and rate limits as servers struggled to absorb millions after millions after millions of new arrivals.
In the same way, despite not having the backing of a major publisher or professional writers, Wikipedia not only outlasted Encyclopedia Britannica, it became synonymous with current, up-to-date and reliable knowledge. Arguably, Wikipedia was even a Web 2.0 organization way before Web 2.0 was a thing, despite being unapologetically Web 1.0 and non-commercial. After all it just set the rules for nerds to have passionate debates about who was right while throwing citations and arguments and each other, with the reward being to have their worlds chiseled for the world to see and refer to.
And for both of them, it was the frail web of gifting that choked the giants in the end. In the same way, as Firefox prevailed over Explorer, Linux prevailed over Unix, Python prevailed over Matlab and R prevailed over SAS.
Perhaps because the most valuable aspect of the web of giving is not the monetary gifts, it’s the gift of time and knowledge by the developers.
Signal could have never survived waiting for a decade before it got wide-spread adoption, if it had to pay salaries of the developers of the caliber that contributed and supported it. Wikipedia could have never paid the salaries of all the contributors, moderators and admins for all the voluntary work they did. Linux is being sponsored by a number of companies to add features and security patches, but the show is still ran by Linus Torvalds and the devs mailing list. Same for Python and R.
It’s not only the voluntary work that’s a non-monetary gift. Until not too long ago people were donating their own resources to maintain projects online without a single central server – torrenting and Peer-to-Peer. Despite a public turn towards centralized solutions with regulations and ease-to-use, it’s still the mechanism by which Microsoft distributes Windows updates and it’s the mechanism by which PeerTube works.
Perhaps more interestingly, we now have pretty good algorithms to build large byzantine-resilient systems, meaning a lot of shortcomings with trust Peer-to-Peer had could now be addressed.