After 6 years, Mastodon is finally in the news. And for all the right reasons.
And a lot of people in tech have written about what they think about Mastodon and its future, including ones that I think very highly of, notably “Malwaretech” Marcus Hutchinson (here and here) and Armin Ronacher (here). Go give them a read, they are great insight.
Unlike them, I’ve been on Mastodon on and off (but mostly off) since early 2017, in large part due to missing people I was interested in interacting with there.
Back in 2017 I checked out Mastodon as a potential destination for then nascent science Twitter, if we were kicked off the platform by Trump and his friends, for going againts their agenda.
It might sound a bit paranoid now, but back at the time, NOAA, NSF and EPA archives of climate data and polution were taken down and a certain Andrew Wakefield was invited as a guest of honor at Trump’s Inauguration ceremony. Twitter haven’t taken any stance on fact-checking, scientists harassment or highly vocal antivax propaganda (Vaxxed movie was for instance advertised open and wide there). Facebook was going to roll with whatever the power would have wanted it to do anyway, and for pretty busy MDs and scientists figuring out yet another forum/social network was going to be a hassle. And IRC for sure was out of question.
In the save-the-scientific-date antiscientific new order world we were going to fight against, Mastodon instances would be indexes for scientific datasets torrent magnets and their hashes to prevent tampering and flooding. Complete with VPN, GPG hash re-signing, and hash registration on the Bitcoin blockchain (I couldn’t believe NFTs were not actually that when I first heard of them).
In hindsight, we might have gone full cyberpunk. And yet, we might have just been on advance on our time.
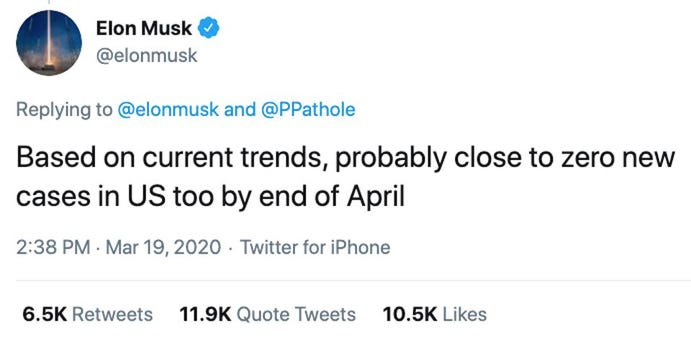
Five years later, and an aggressively anti-science billionaire hast taken over Twitter and is kicking off anyone he doesn’t like from his platform.
The Great Mastodon Migration(s)
With a lot of people among my contacts now seeing the sign on the wall for Twitter, the issue of Mastodon being empty is now solved for me. I now see there most of the people I followed and interacted on a day-to-day basis on Twitter are now on Mastodon too, mostly interacting in the same way.
Most. And mostly.
As for many tech people and early adopters, I am a bit different from an average user. I am no Linus Torvalds, Steve Wozniak, Dennis Ritchie, or even your middle-of-the road hacker. Bit-by-bit inspection of compiled code to debug or find an exploit is not my idea of good time, but I am still able to jump on a new tech or platform and mostly figure its head and tail, even if it looks off and I need to crawl stackoverflow, reddit and man pages to figure out how to do what I want with it.
Needless to say, I am a minority. A lot of Twitter’s features were getting in the way for me. For instance my timeline has been almost exclusively in chronological and I had add-ons to unfold twitter thread storms into trees to be able to follow it and track people I talked to, because Twitter’s prioritization miserably failed.
But that also meant that Mastodon was a frictionless transition for me. It already worked the way I wanted Twitter to work, except better – more granular control on post visibility, no surprise sponsored posts, and a simpler verification process (rel=”me” FTW!).
It was all but for a lot of my contacts, who struggled to figure out what it was and how it worked.
Roadblocks in the fediverse
Trust into instances.
Twitter is simple. You say to people you are on Twitter, you give them your handle (@JohnDoe) and they can go on Twitter and follow you. @JohnDoe1, @JohnDoe87, @JohnD0e will be other people and you will not be following and interacting with them. With a bit of luck, you are visible enough to earn a blue checkmark and people looking for you will be able to distinguish your account from all the others.
On Mastodon, things are much less clear if you think like a Twitter user.
There is a @JohnDoe@mastodon.social, there is @JohnDoe@infosec.exchange, there is @JohnDoe@SanFrancisco.city. Are they all the same person? If not, which one is the one you need?
If you want to start your account, what does choosing an instance changing?
- Which ones will protect your private information, and which ones will get hacked?
- Which ones will allow you to follow your friends and which ones will get de-federated? Or block instances your friends are on?
- What are the rules of your instance, and who is enforcing them?
- Can you criticize and oppressive government? Does your instance admin has enough legal protection to keep you safe against a small dictatorship?
- Can you post gore from a recently bombed city to raise awareness, or will it get you kicked or your instance – defederated?
- How reliable will the service be? Will you be able to connect when you want to? Or is it going to be a FailPachyderm 24/7?
Over the years, Twitter built themselves a reputation, which made clear what users could expect. At least until Musk nuked it in about 7 days, re-nuking it about once a day since, just in case.
For Mastodon, things are more complicated – basically every instance is it’s own “mini-Twitter” and when push comes to shove it’s not clear if they will stand together or fall one by one. There is some trust towards the largest “mastodon.social”, ran by the Mastodon non-profit itself, but it has no means to scale at the speed of new users arrival, even less to moderate them all. That’s not how Mastodon or Fediverse are supposed to work to start with.
And the problem is that those questions are questions of life and death for opponents to oppressive regimes, citizens trying to survive to them or soldiers on battlefield. Life of protestors in Iran depends on whether the authorities can get to their real name – by injunction or by hacking. Same for women looking for abortion in red states in the US. Ukrainian soldier’s unit depends on whether the instance removes the meta-data from images and reminds them about OPSEC and blurring.
Those people specifically are missing from Mastodon online and are still on Twitter or are erroneously moving to Telegram, that a lot of oppressive regimes can easily track.
Part of it is educating users and changing the mentality from “it’s Twitter, but for hipster hackers” to “It looks like Twitter, but it’s more of emails”.
Part of it is actually addressing the structural instances right now. A lot of people I’ve heard touching the topic believe it’s not possible without corporate instances making enough profit to protect their users.
I disagree.
No-profits like EFF, La Quadrature du Net, ACLU have been set up specifically to help small organizations with user interests in mind stand up to and fight large organizations with the opposite of user interests in mind. Mozilla, Apache, Linux and Python foundations has been able to provide real-time critical maintenance and support making their products safe to use and deployed with an excellent safety record.
There is no reason those players and foundations couldn’t bring Mastodon foundation up to speed and provide it with instance vetting/certification process and an umbrella coverage to them. It won’t be pre-Musk Twitter, but it might be for the better.
Basically EFF, ACLU and someone like Mozilla need to bring together their powers to create trusted instances and someone like Wikipedia will need to give them a primer on moderation.
Search.
Mastodon does not allow full-text search. Period. That’s by design. You can search for users or hashtags, and you can do full-text searches of your own posts.
You can’t however do a full-text search of your own instance and much less of the fediverse. Once again, that’s by design.
And if you remember the neo-nazi harassment campaign on Twitter against “jewish” accounts back in 2016, with their (((@<account>))), you will agree it makes sense. Besides, fuzzy whole-text indexing and searching are rather expensive operations. In absence of personal data scouring for info that could be used to target ads, it makes no business sense to have it.
However, it also makes Mastodon useless for a lot of people who relied on Twitter to do their job- journalists, scientists, malware analysts, or even critical emergency response.
Journalists were able to zero in on an event or find new information – starting with images posted by some of Jan 6 2021 Capitol Rioters attacks to finding the people combining an in-depth, engaging writing with deep expertise in topics such as COVID. Or find published images of war crimes such as Bucha massacres posted in real time and be able to validate them to make a timely story.
Scientists were able to find people talking about their latest paper or preprint and either address the shortcomings or get a better idea of what to do in the future. Or alternatively look for valid criticism of papers they were going to ask their PhD students to base their work off. With a number of scientific fraud sleuths on Twitter, there are good chances that a search like could lead to project adjustment and save years to the student and hundreds of thousands in funding.
Similarly, Malware analysts could do a deep dive into mentions of CVEs or breach numbers to find ideas others would have regarding patching the system or re-configuring the network to decrease their vulnerability to the attacks.
But perhaps the most critical is emergency incident response. With Twitter, people tweeted about hurricanes hitting them and destroying their houses, cutting water and power, earthquakes they felt, tornadoes that removed their neighbor’s house, smell of gas, symptoms of a disease – you name it. They became essential to the assessment of the situation and decision-making for the search and rescue operations. And given that no one in their right mind would be adding hashtags in their tweets while overwhelmed with feelings and fear, and surely not spelling them right, full-text search was essential to their work.
All of those applications are unquestionable social good and were made possible by Twitter’s full-text search. Mastodon needs to find a way to replicate such search for those applications, even if based on clearances or specific terms.
Commercial content
Another social good that Twitter unintentionally brought with it was companies accountability. Thanks to the search and open APIs (at least for a relatively moderate cost), commercial companies could track their customers sentiment and feedback and jump on anything that could be a request for the support.
While it led to several comical interactions and led to abuse from MLM and web 3.0 Ponzi schemes, the public visibility of their reaction definitely led companies to move it lest they were going to loose customers due to rumors of bad service and bad customer service.
Moreover, a lot of consultants, authors and freelancer lived and died by their Twitter reputation and engagement. LinkedIn is for making pompous announcement in corporatespeak. Twitter is about the “here’s how you do it kids, and here’s the reasons why doing it in that other way is a bad idea”. It was a place to show and prove competence in the domain and get visibility to people who would provide them with contracts and ultimately income. Twitter allowed people more independence and better put forwards their expertise.
However, the reasons they could do it is that they decisionmakers with budgets in their domains already were on Twitter, even if it was for hot takes about the latest sportsball event or to follow a celebrity in hopes to interact with them.
The reality is that commercial content is part of everyone’s life and the way the overwhelming majority of people make money. Mastodon cannot stand on its own if it doesn’t provide a space to talk about it and a space for commercial players to engage at least in some form and people to reach for commercial context in at least some form.
Rules by which commercial companies operate are radically different from FOSS. They need predictability, reliability and protection against impersonation (the whole reason behind Twitter blue checkmarks). There are companies that can do both, but they are few and far in between. And tbh, it’s mostly Red Hat.
Mastodon needs its own Red Hat to emerge and will need to figure out conditions on which the federated instances will let the commercial entities come into fediverse if it is to stand on its own as a social network.
Context
Mastodon home timeline is confusing. At least in the base web interface.
You are greeted with tibits of unrelated conversation without an ability to identify immediately which threads do they fit on, who is that person your friends are boosting, or what is behind that link they are sharing. It just lacks context to be able to fully leverage it.
The <First Tweet> … <Tweets from your friends you haven’t seen yet> feature on Twitter sucked big time – in part because it was impossible to find what the … actually were about unless you got lucky. But it at least provided some context to understand what you were jumping back in.
Similarly, the expansion of URLs into a square that at least includes the header and a short excerpt of the abstract on Twitter was not without its downside, but provided enough context to the link for you to understand what it was about and decide where you were clicking on it.
Finally the show-info-on-hoover for accounts was quite vital to figure out how trustworthy/competent the person behind the post was. Especially once combined with checkmarks (no matter how problematic they were), allowing to tell whether the person really was who they said they were.
Speaking of validation, while the validation is working on Mastodon with the <rel="me"> tag, and could be improved with dedicated instances, they are both prone by domain look-alike squatting. De-facto trust in Web 2.0 is provided by platforms (eg Google search), making sure you are landing on your bank’s account rather than a lookalike built for phishing. Mastodon will need to figure something out, simply because the name or even domain-based trust schema of Web 1.0 is simply too unsafe for the vast majority of users, no matter how tech-saavy.
Similarly, the blue checkmarks is not sufficient context. Yes, an MD with a degree of pandemics preparedness, virology and contagious diseases epidemiology is a good person to listen to regarding COVID news and opinions. An MD with a gastroenterology degree and obesity epidemics expertise is probably not. Yet a blue checkmark is not enough to distinguish them, or even an instance name. There is a need to provide more context about people and their expertise that’s visible at a glance.
Mastodon will need to figure out how to provide enough context while not making editorial decisions and leaving fediverse free, be it with regards to just helping the user or ensuring safety in high-stakes applications.
It might mean that dedicated high-visibility validated instances (EFF/Quadrature/ACLU/Mozilla) will take an outsized importance in the fediverse. It might mean commercial instances. It might mean rules about names proximity. But it will need to be figured out.
Algorithm(s)
The Algorithm is seen as **evil** by the better part of civil liberties advocates, including Mastodon developers and community. The whole promise of Mastodon is to remove the algorithmic censorship of free speech large corporations inevitably put in place and just let you see everything your friends are posting, in the order they are posting.
And I understand that stance. I’ve ran my Twitter feed sorted by newest first most of the time, even after they introduced algorithmic prioritization. It mostly worked for me.
Mostly.
As long as I was following people that were tweeting approximately the same amount of equally important information, it worked well.
It went out of the window as soon as some of them went into a tweeting spike and basically flooded your timeline with retweets of tweets announcing their next event (book signing), or reactions to their latest blog post, or supporting their side in their latest flame war. Good for them, but while scrolling past the tweets of no interest to you, chances you were going to skip something important or critical – like an announcement from an intimate friend for their wedding, promotion, or a prize.
The important signal gets drowned in chaff and meant that even me, with my measly 800 accounts followed had to regularly switch to algorithmic Twitter timeline to catch up on anything I could have missed over the last 4-5 days. For people following the same number of accounts in a more professional setting, the whole chronological timeline becomes an insanity – a non-stop Niagara of new posts rapidly appearing and disappearing as other posts come to take their place. No human can process it all, especially if they spend only a 15-30 minutes a day on that social media.
That’s why prioritization algorithms became popular with users in the first place.
However, algorithms developed by twitter Twitter/Facebook/Google/Youtube/… don’t serve the interest of their users. In the web of ads, attention, engagement and retention are everything. Algorithms built by companies are there to serve the interest of companies first and foremost, user well-being or even safety be damned.
The web of gifting is free of that pressure, but also is lacking resources to develop, train and deploy SotA ML solutions. However SotA is usually not necessary and the benefit of even basic recommendation algorithms is so high that on several occasions I considered writing an independent Twitter client just to have a prioritization algorithm that worked the way I wanted it to.
On Mastodon, it would be at least masking of boosting of tweets I’ve seen before or earlier tweets in a thread I’ve already read by starting from one of the most recent posts. Yes, you can implement your client doing it the way you want, but it’s just not realistic for the vast majority of users – even highly tech advanced. We need a solution about as easy as an “algorithm store”, be it more of a pip or apt or an AppStore. Algorithms can easily be developed by users and shared among them, either for personal use or for distributed privacy-preserving learning.
Mastodon just needs support for personalized algorithms and a way to distribute them and let users choose which ones they want to run.
Moderation
Scaling moderation is a hard task. As of now, the fediverse managed to do it with de-federation and within-instance moderation of federated instances. And lack of valuable targets for harassment,
It is a good solution for the world of small instances and a fediverse with a reasonable amount of instances. With mega-instances, such as for instance the mastodon.social, now at 90 000 users, moderation is unreasonable and smaller instances are already de-federating.
As users will keep migrating into the fediverse (and I do believe they will), there are likely won’t be enough separation of users by interests and communities to avoid mega-instances, especially in the contexts where the likely moderators would impede free speech (eg academic supervisors in academic instances preventing students from warning one another about some top-level academicians’ behaviors).
The moderation of large instances and will become a big problem.
Twitter was riding a thin line between moderating to the point of editorializing and letting abuse run rampant. 2011 Arab Spring protester were on Twitter because it didn’t bulge on their dedication to user protection against abusive regimes – thing on which Microsoft, Google and Facebook didn’t hesitate to bulge. That’s why Arab Spring happened on Twitter. In 2013 peoples who were being vocal about their hate to companies advertising on Twitter were once again let to be vocal rather than de-amplified or outright silenced. That’s how Twitter became the platform to go to with complaints about service or experience and be heard and treated for support in priority. With rampant abuse by state actors seeking to manipulate the public opinion in 2015 and 2016, anti-science disinformation campaigns against vaccines, climate change and pollution in 2016-2019, and then on COVID starting from 2020, and finally Trumps’ call on the insurrection, the moderation became more and more difficult and politicized until fact-checking billionaires brought the demise of Twitter.
However, the most important reason Twitter was credible in their actions was that it opened itself to the external supervision. While Facebook and Google fought against anyone willing to have a look into what was going on their platforms (starting with their own employees), even if it meant they were being complicit in a genocide, Twitter opened it’s platform to researchers for basically free, providing top-tier data access usually reserved for internal use or trusted partners. Even if it meant a deluge of reports came in highlighting hate speech, narratives twisting and information operations, Twitter allowing it and sometimes acting on it still allowed public trust into Twitter as platform, as it was eroding to pretty much everyone of its competitors. It all led people believe Twitter was a hellsite. In reality, it was better than others, just not censoring reports about the problems it might have had.
The mechanisms driving those issues haven’t gone anywhere. They are still here and will start impacting Mastodon and fediverse as it grows.
FOSS doesn’t have billions in ad, premium or VC money to throw at the problem like online giants do.
However it is able to leverage the goodwill and gift of the time from its users as volunteers to achieve the same thing.
Wikipedia, among all, achieved a ubiquitous status as the last instance of truth in the internet, in large part thanks to the moderation model it is running, letting people argue with facts, publicly available information and academic writing until they get to a stalemate that’s pretty representative of the scientific consensus or public knowledge about facts.
It has pretty big issues, notably with women and minorities representation or coverage from minorities narratives. It still did a better job than most large platforms, to the point they started using Wikipedia information in their own moderation decisions.
But Mastodon is not Wikipedia. Fediverse will need to keep figuring out its moderation rules, especially as the stakes keep rising as more and more users join it and larger and larger instances emerge.
Hitting the main street.
I am optimistic about Mastodon and fediverse overall, in large part because it’s a protocol and a walled garden.
And also perhaps because I really want it to work out.
For all its shortcomings, pre-Musk Twitter was a great tool and in a lot of ways made transformations in this world possible, ranging from democratic revolutions to people just getting a better customer service.
And for all its past greatness, Twitter to me is now dead, because what was making it so unique – trusted moderation team – is now dead and will not be coming back to it.
For me personally, the mix of pretty much everyone on there – ranging from scientific colleagues to infosec and disinformation experts, to OPSEC experts to journalists and columnists allowed me to keep the hand on the pulse of the world, professionally, and have the best insight possible not only into the current state, but also project into the future, often further than most other news outlet would have allowed me to.
Unlike a lot of my colleagues, I don’t think that the lack of average Joes on Mastodon is such a big issue for scientific outreach. After all most people don’t listen to some random dude on the internet. They are listening to their local opinion leader, someone they know knowledgeable in their domain, and whose opinion they think extends to other domains. If those people are connected, the outreach still works out.
I also don’t see people coming back to Twitter if the management has a sudden change of heart and a new management comes in. Trust is really slow to build and is easily lost. There is no guarantees new Twitter won’t go deleting users’ critical comments, banning accounts on a whim or perform algorithmic manipulations. People in tech are painfully aware of it; journalists are becoming more and more aware and the general public who don’t care for it, also don’t see any advantages to Twitter over Facebook, TikTok, Instagram or a myriad of other, more engaging and less serious social medias.
Similarly, unlike a lot of my contacts over on Twitter, I don’t think that a social media being commercial is a fatality. I am seeing Mastodon evolving and becoming a healthier alternative to the social media while keeping good things about them and dropping the less good things. FOSS worked out in the past, there is no reason it has to fail now.
In the end, thanks to Musk, Mastodon is now alone in the field, ready to grow and provide to people a better alternative. The only thing that could undermine its growth is itself – its users and its developers.
But that’s a part of the deal. I certainly hope they will find a way forwards and be willing to accept change, no matter how scary.