FiveThirtyEight’s 2016 election forecast and Nassim Taleb
Back in August 2016, Nassim Nicholas Taleb and Nate Silver had a massive and a very public run-in on Twitter. Taleb – the author of “Black Swan” and “Antifragile” and Nate – the founder of FiveThirtyEight were arguably the two most famous statisticians alive back at the time, so their spite ended up attracting quite a lot of attention.
The bottom line of the spat was that for Taleb, the FiveThirtyEight 2016 US presidential election model was overly confident. As the events in the race between Clinton and Trump swung the vote intentions one way or another (mostly in response to the quips from Trump), Nate’s model’s forecasts had too large swings in its predictions and confidence intervals to be considered a proper forecast.
Taleb did have a point. Data-based forecasts, be they based on the polls alone or more considerations, are supposed to be successive estimations of a well-defined variable vector – aka voting splits per state, translating in electoral college votes for each candidate on the day of the election. Any subsequent estimation of that variable vector with more data (such as fresher polls) is supposed to be a refinement of the prior estimation. We expect the incertitude range of the subsequent estimations to be smaller than the one of the prior estimation and to be included into the prior predictions incertitude range – at least most of the time, modulo expected errors.
In the vein of the central thesis of “Black Swan”, Taleb’s shtick for 2016 election models – and especially the FiveThrityEight’s one – was that they were prone to overconfidence they had in their predictions and underestimated the probability of rare events that would throw them off. As such, according to him, the only correct estimation technique would be a very conservative one – giving every candidate 50/50% chance of willing right until the night of the election, when it would jump to 100%.
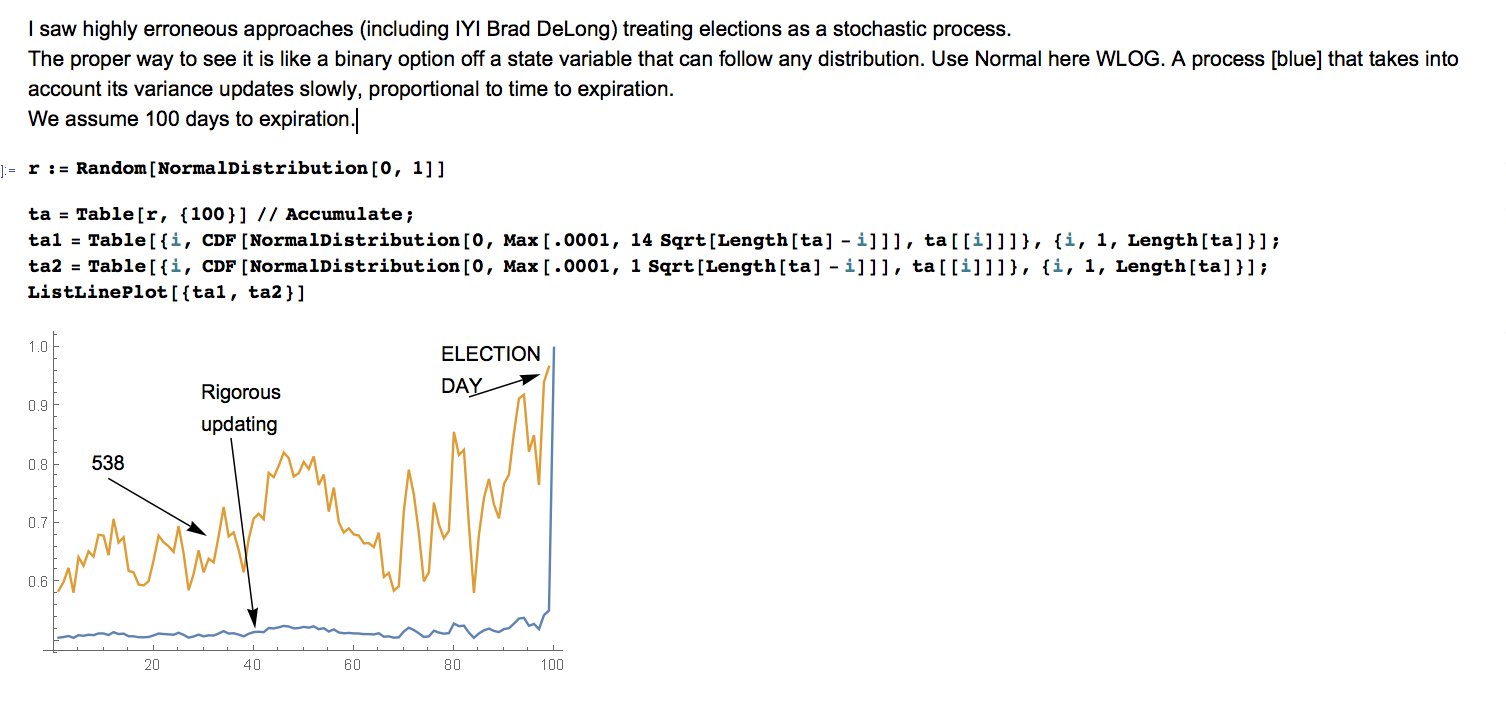
The thing is that Nassim Nicholas Taleb is technically correct here. And Nate Silver was actually very much aware of that himself before Taleb showed up.
You see, the whole point of Nate Solver creating the FiveThirtyEight website and going for rigorous statistics to predict games and election outcomes was specifically the fact that mainstream analysts had hard time with probabilities and would go either for a 50/50 (too close to call), or a 100% sure, never in-between (link). The reality is that there is a whole world in between and that such rounding errors would cost you dearly. As anyone dealing with inherently probabilistic events would painfully learn, for an 80% win bet, you still loose 20% of the time – and have to pay dearly for it.
Back in 2016, Nate’s approach was to make forecasts based on the current state of the polls and the estimation of how much that could be expected to change if the candidates were doing about the same thing as the candidates in past elections. Assuming the candidates don’t do anything out of the ordinary and the environment doesn’t change drastically, his prediction would do well and behave like an actual forecast.
Nate explains what is a forecast is to him
The issue is that you can never enter the same river twice. Candidates will try new things – especially if models show them as loosing if they don’t do anything out of the ordinary.
Hence Taleb is technically correct. Nate Silver’s model predictions will always be overly confident and overly sensible to changes resulting from candidate’s actions or previously unseen changes in the environment.
Decidability, Turing, Solomonoff and Gödel
However Taleb’ technical correctness is completely besides the point. Unless you are God himself (or Solomonoff’s Demon – more about that in a second), you can’t make forecasts that are accurately calibrated.
In fact, any forecast you can make is either trivial or epistemologically wrong – provably.
Let’s for a second imagine ourselves physicists and get a “spherical cow in vacuum” extremely simplified model of the world. All the events are 100% deterministic, everyone obeys well-defined known rules, based on which they will make their decisions, and the starting conditions are known. Basically, if we had a sufficiently powerful computer, we can run the perfect simulation of the universe and come up with the exact prediction of the state of the world and hence of the election result.
Forecast in this situation seems trivial, no? Well, actually no. As Alan Turing – the father of computing – have proved in 1936, unless you run the simulation, in general you cannot predict even if a process (such as voter making up his mind) will be over by the election day. Henry Gordon Rice was even more radical and in 1951 has proven a theorem that can be summarized as “All non-trivial properties of simulation runs cannot be predicted”.
In computer science, forecasting if a process will be over is called halting problem and is known as a prime example of a problem that is undecidable (aka, there is no method to predict the outcome in advance). For those of you with an interest in mathematics, you might have noted a relationship to Gödel’s incompleteness theorem – stating that undecidable problems will exist for any set of postulates that are complex enough to embed the basic algebra.
Things only go downhill once we add some probabilities into the mix.
For those of you who have done some physics, you probably have recognized the extremely simplified model of the world above as Laplace’s demon and have been screaming on the screen about the quantum mechanics and how that’s impossible. You are absolutely correct.
That was one of the reasons that pushed Ray Solomonoff (also known for the Kolmogrov-Solomonoff-Chaitin) to create something he called Algorithmic Probability and a probabilistic pendant to Laplace’s demon – Solomonoff’s demon.
In the Algorithmic probability frameowrlk, any possible theory about the world that can exist has some non-nul probability associated to it and is able to predict something about the state of the world. And to perform an accurate prediction about the probability of the event, you need to calculate the probability of that event according to all theories, weighted by the probability of each theory:

E is event, H is a theory, sum is over all possible theories
Fortunately for us, Solomonoff also provided a (Bayesian) way of learning the probabilities of events according to theories and probabilities of theories themselves, based on the prior events:

D is new data, H is a theory, sum is over all possible theories T, but excluding theory H
Solomonoff was nice enough to provide us with two critical results about his learning. First, that it was admissible – aka optimal. In other terms, there is no other learning mode that could do better. The second – that it was uncomputable. Given that a single learning or prediction step requires an iteration over the entire infinite set of all possible theories, only a being from a thought experiment – Solomonoff’s demon – is actually able to do it.
This means that any computable prediction methodology is necessarily incomplete. In other terms, it is guaranteed not to take in account enough theories for its predictions to be accurate. It’s not a bug or an error – it’s a law.
So when Nassim Taleb says that Nate Silver’s model overestimates its confidence, while technically correct, is also completely trivial and tautological. Worse than that. Solomonoff also proved that in general case, we can’t evaluate by how much our predictions are off. We can’t possibly quantify what we are leaving on the table by using only a finite subset of theories about the universe.
The fact that we cannot evaluate in advance by how much we are off in our predictions basically means that all of Taleb’s own recommendations about investments are basically worthless. Yes his strategy will do better when there are huge bad events that market consensus did not expect. It will however do much worse in case they don’t happen.
Basically, for any forecasts, the, best we can do is something along the lines of Nate Silver’s now-cast + some knowledge gleaned from the most frequent events that occurred in the past. And that “frequent” part is important. What made the FiveThirtyEight model particularly bullish about Trump in 2016 (and in retrospect most correct) was its assumption of correlation of polling errors across the states. Without it, it would have given Trump 0.2% chances to win instead of 30% it ended up giving him. Modelers were able to infer and calibrate this data because it occurred in every prior election cycle.
What they couldn’t have properly calibrated (or included or thought of for the matter) were one-off events that would radically change everything. Think about it. Among things that were possible, although exceedingly improbable in 2016 were:
- Antifa militia killing Donald Trump
- Alt-right militia killing Hilary
- Alt-right terrorist group inspired by Trump’s speeches blowing up the One World Trade Center, causing massive outrage against him
- Trump making an off-hand remark about grabbing someone’s something that would outrage the majority of his potential electorate
- It rains in a swing state, meaning 1000 less democratic voters decide last second to note vote because Hillary’s victory is assured
- FBI director publicly speaking about Hillary’s emails scandal once again, painting her as corrupt politician and causing a massive discouragement among potential democrat voters
- Aliens showing up and abducting everyone
- ….
Some of them were predictable, since they happened before (rain) and were built into the model’s uncertainty. Other factors were impossible to predict. In fact, if in November 2015 you would have claimed that Donald Trump will become the next president due to the last-minute FBI intervention, you would have been referred to the nearest mental health specialist for urgent help.
2020 Election
So why write about that spat now, in 2020 – years after the fact?
First, it’s a presidential election year in the US, again, but this time around even with more potential for unexpected turns. Just as in 2016, Nate’s models is drawing criticism, except this time for underestimating Trump’s chances to win instead of overestimating. While Nate and the FiveThrityEight team are trying to account for the new events and be exceedingly clear about what their predictions are, they are limited in what they can reliably quantify. His model – provably – cannot predict all the extraordinary circumstances that still can happen in the upcoming weeks.
There is still time for the Trump campaign to discourage enough female vote by painting Biden as rapist – especially if FBI reports in the week before the election about an ongoing investigation. There is still time for a miracle vaccine to be pushed to the market. This is not an ordinary elections. Many thing can happen and none of them is exactly predictable. There is still room for new modes for voter suppression to pop up and for Amy Barrett to be nominated to make sure the Supreme court will judge the suppression legal.
And no prediction can account for them all. Nate and the FiveThirtyEight team are the best applied statisticians in the politics since Robert Abelson, but they can’t decide the undecideable.
2020 COVID 19 models
Second – and perhaps most importantly – 2020 was a year of COVID 19 and forecasts associated to it. Back in March and April, you had to be either extremely lazy or very epistemologically humble to not try to build your own models of COVID19 spread or not to criticize other’s models.
Some takes and models were such an absolute hot garbage that the fact they could come from people I have respected and admired in the past plunged me into a genuine existential dread.
But putting those aside, even excellent models and knowledgeable experts were constantly off – and by quite a lot as well. Let’s take an example of expert predictions from March 16th about how many total cases they thought the CDC will have reported on March 29th in the US (from FiveThrityEigth for a change). Remind yourself – March 16th was the time when only 3500 cases were reported in the US, but Italy was already out of the ICU beds and was not resuscitating anyone above 65, France was going into confinement and China was still mid-lockdown.
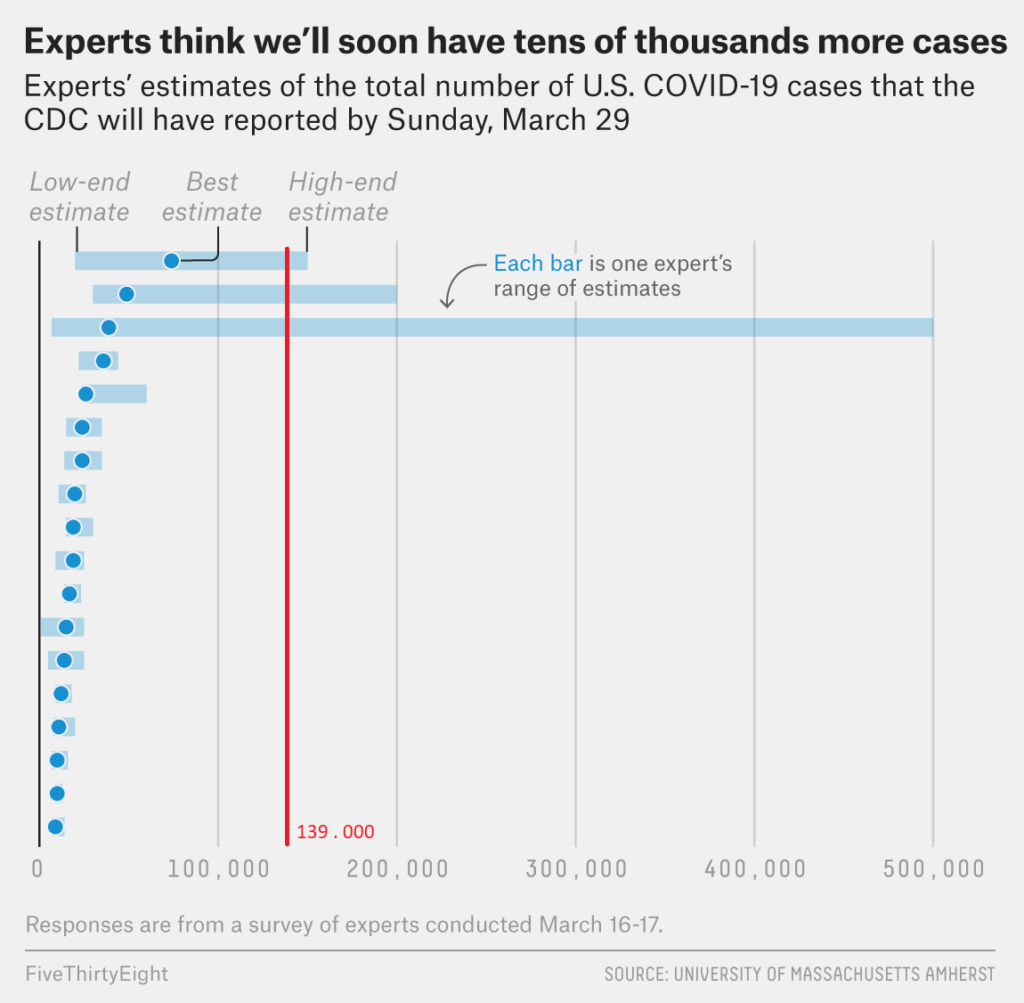
Reality: 139 000 cases
Yeah. CDC reported about 19 000 cases on the March 29th alone. Total was almost 10 times higher than the predicted range and almost the double of the predicted interval. But the reason they were off wasn’t because experts are wrong and their models are bad. Just as the election models, they can’t account for factors that are impossible to predict. In this specific case, what made all the difference was that CDC’s own COVID 19 tests were defective, and the FDA didn’t start issuing emergency use authorizations for other manufacturer’s tests until around the 16th of March. The failure of the best-financed, most reliable and most up-to-date public health agency to produce reliable tests for the world-threatening pandemics for two months would have been an insane hypothesis to make given the prior track record of the CDC.
More generally, all the attempts to predict the evolution of the COVID19 pandemic in the developed countries ran into the same problem. While we were able to learn rapidly how the virus was spreading and what needed to be done to limit its spread, the actions that would be taken by people and governments of developed countries were a total wild card. Compared to the election forecasts, we don’t have any data from prior pandemics in developed countries to build and calibrate models upon.
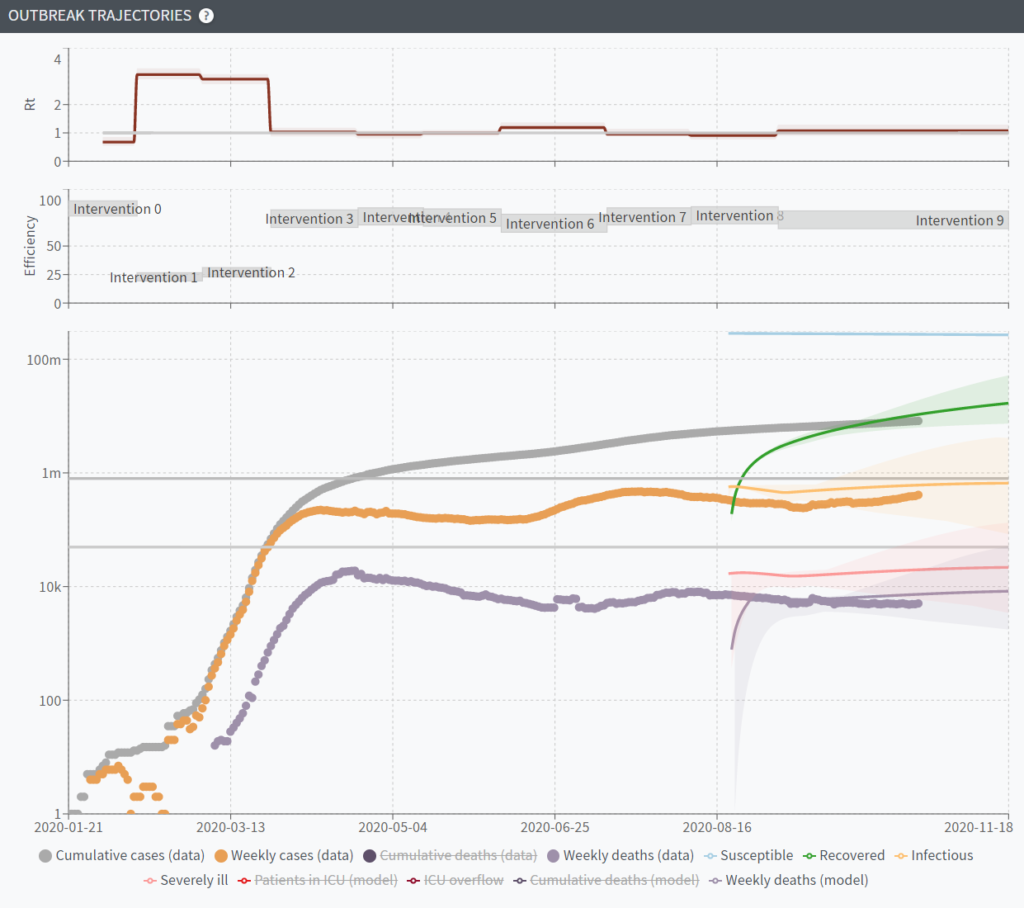
Nowhere is it more visible than in the state-of-the-art models. Here is Youyang Gu’s COVID19 projections forecasting website, using a methodology similar to the one of Nate Silver uses to predict the election outcomes (parameters fitting based on prior experience + some mechanistic insight about the underlying process). It is arguable the best performing one. And yet, it failed spectacularly, even a month in advance.
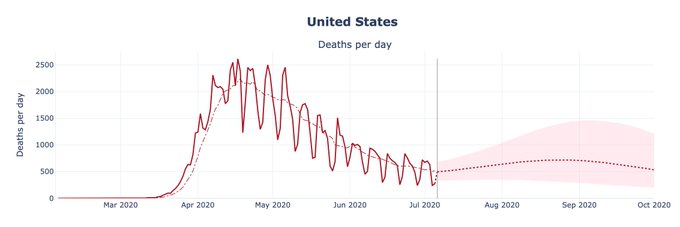
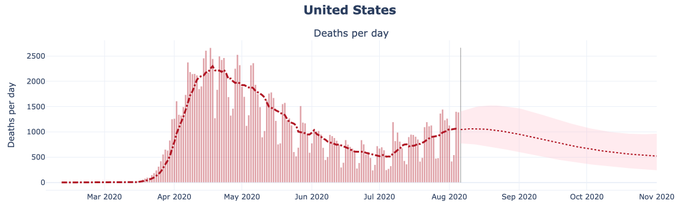
And once again, it’s not the fault of Youyang Gu. A large part of that failure is imputable to Florida and other Southern states doing everything to under-report the number of cases and deaths attributed to COVID19.
The model is doing as well as it could, given what we know about the disease and how people have behaved themselves in the past. It’s just that no model can solve the halting problem of “when will the government decide to do something about the pandemic, what it will be and what people will decide to do about it”. Basically the “interventions” part of projections from Richard Neher’s lab COVID19-scenarios is as of now undecidable.
Another high-profile example of expert model failure is the Global Health Security Index ranking for countries best prepared for pandemic from October 2019. US and the UK received respectively the best and second best scores for pandemic preparedness. Yet, if we look today (end of October 2020) and the COVID19 per capita among developed countries, they are a close second and third worst performers. They are not an exception. France ranked better than Germany. Yet it has 5 times the number of deaths. China, Vietnam and New Zealand – all thought to be around the 50/195 mark are now the best performers, with a whooping 200, 1700 and 140 times less deaths per capita than the US – the supposed best performer. All because of difference in the leadership approach and how decisive and unrelentless the response to the pandemic from the government was.
GHS index is not useless – it was just based on the previously implicit expectation that governments of countries affected by the outbreaks would aggressively intervene and do all in their capacity to stop the pandemic. After all, USA in the past went as far as to collaborate with the USSR, at the height of the Cold War to to develop and distribute the polio vaccine. It was after all what was observed during the 2010 Swine flu pandemic and during the HIV pandemic (at least when it became clear it was hitting everyone, not just the minorities) and in line with what WHO was seeing in developing countries hit by pandemics that did have a government.
Instead of a conclusion
Forecasting is hard – especially when it is quantitative. In most of cases, predicting what will happen deterministically is impossible. Probabilistic predictions can only base themselves on what happened in the past frequently enough to allow them to be properly calibrated.
They cannot – provably – account for all the possible events, even if we had a perfectly deterministic and known model of the world. We can’t even estimate what the models are leaving on the table when they try to perform their predictions.
So the next time you criticize an expert or modeler and point a shortcoming in their model, think for a second. Are you criticizing them for not having solved the halting problem? Not having bypassed the Rice theorem? Built an axiome set that does not account for a previously un-encountered event? Would the model you want require a Laplace or a Solomonoff Demon to actually run it? Are you – in the end – betting against Turing?
Because if the answer is yes, you are – provably – going to lose.
===========================
A couple of Notes
An epistemologically wrong prediction, can be right, but for the wrong reason. A bit like “even the stopped clock shows the correct time twice a day”. You can pull a one-off, maybe a second one if you are really lucky, but that’s about it. That’s one of the reasons for which any good model can only take in account events that has occurred sufficiently frequently in the past. To insert them into the model, we need to quantify their effect magnitude, uncertainty and the probability of occurrence. Many pundits using single-parameter models in 2016 election to predict a certain and overwhelming win for Hillary learnt it the hard way.
Turing’s halting problem and Rice theorem have some caveats. It is in fact possible to predict some properties of algorithms and programs, assuming they are well-behaved in some sense. In a lot of cases it involves them not having loops or having a finite and small number of branches. There is an entire field of computer science dedicated to developing methods to prove things about algorithms and to writing algorithms in which properties of interest are “trivial” and can be predicted.
Another exception to Turing’s halting problem and Rice’s theorem is given by the law of large number. If we have seen a large number of algorithms and seen the properties of their outcomes, we can make reasonably good predictions about the statistics of those properties in the future. For instance we cannot compute the trajectories of individual molecules in a volume, but we can have a really good idea about their temperature. Similarly, we can’t predict if a given person will become infected before a given day or if they will die of an infection, but we can predict the average number of infections and the 95% confidence interval for a population as a whole – assuming we did see enough outcomes and know the epidemiological interventions and adherence. That’s the reason, for instance, why we are pretty darn sure about how to limit COVID19 spread.

To push the point above further, scientists can often make really good prediction from existing data. Basically, that’s how scientific process work – only theories with confirmed good predictive value are allowed to survive. For instance, back in February we didn’t know for sure what was the probability of the hypothesis “COVID19 spreads less as temperature and humidity increases”, nor what would be the effect on spread. We had however a really good idea that interventions such as masks, hand washing, social distancing, contact tracing, at-risk contacts quarantine, rapid testing and isolation would be effective – because of all we learnt about viral upper respiratory tract diseases over the last century and the complete carnage of the theories that were not good enough at allowing us to predict what would happen next.
There is however an important caveat to the “large number” approach. Before the large numbers laws kick in and modeler’s probabilistic models become quantitative, stochastic fluctuations – for which models really can’t account – dominate and stochastic events – such as super spreader events – play an outsized role, making forecasts particularly brittle. For instance, in France the early super spreader event in Mulhouse (mid-February) meant that Alsace-Moselle took the brunt of the ICU deaths in the first COVID19 wave, followed closely by the cramped-up and cosmopolitan Paris region. One single event, one single case. Predicting it and its effect would have been impossible, even with China-grade mass survelliance.

If you want to hear a more rigorous and coherent version of the discussion about decidability, information, Laplace-Bayes-Solomonoff and about automated model design (aka ML/AI mesh with all of that), you can check out Lê Nguyên Hoang and El Mahid El Mhamdi. A lot of what I mention is presented rigorously here, or in French – here.